夜思为一系列思考文章,不仅在于对未来技术的畅想,也会脚踏实地瞄准各类社会现象抑或是产品。将会不定期更新,此篇为Vol.1。
读者必备知识点
阅读开始之前,你需要具备基础的独立思考的能力,并不一定需要你对深度学习、代码等有深入的了解,但是你需要
基础环境:Windows10 Python>=3.8 进阶环境:cuda pytorch tensorflow 外网连接能力
在文章开始之前,读者首先要了解以下概念,以便更好的理解本文章。
API (Application Programming Interface): 应用程序接口,是一组定义软件组件的接口,用于定义软件如何与其他软件交互。
自然语言处理(NLP): 自然语言处理(英语:natural language processing,缩写:NLP)是计算机科学、人工智能和语言学领域的交叉学科,旨在实现计算机和人类之间的自然语言通信。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。
大型语言模型(LLM): 大语言模型(英语:large language model,LLM)是一种语言模型,由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成,使用自监督学习或半监督学习对大量未标记文本进行训练。[1]
- (Multimodal): 在深度学习中,指的是结合多种不同感知模态(如图像、语音、文本等)的数据来进行分析、理解和处理的方法和技术。
- (AI hallucination): AI幻觉是指深度学习中模型生成的虚假信息,就比如,你交给AI一道数学题,AI有可能输出根本不存在的公式并且告诉你这是正确答案。[2]
- : 在深度学习中,Prompt是指一种输入方式,用户可以通过Prompt来指导模型生成特定的输出,在实际操作中,Prompt通常是一段文本,用户可以通过修改Prompt来控制模型的输出。
OCR(Optical Character Recognition): 光学字符识别(OCR)是指将图像中的文本转换为可编辑的文本,通常用于将印刷或手写文本转换为数字文本,目前OCR技术已经相当成熟,如果你使用过图片转文字,那个就是OCR技术。
- : Transformer是一种基于注意力机制的神经网络架构,最初由Google Brain团队提出,用于自然语言处理任务,Transformer模型在深度学习领域有着广泛的应用。
huggingface: huggingface是一个提供各种AI模型的开源社区。
前言
发展时间线
2022年11月30日,OpenAI公布了一个通过由GPT-3.5系列大型语言模型(LLM)微调而成的全新对话式AI模型ChatGPT,它不仅能实现简单的问答,还能实现上下文感知,多轮对话,还能生成代码,完成许多过去AI根本做不到的事情,使其迅速破圈,不仅在科研,AI的小圈子爆火,也迅速吸引许多普通人使用。
2023年1月末,OpenAI宣布其用户已经突破1亿。
与此同时,国内外各个大厂纷纷跟进LLM的应用,国外以谷歌、微软、Meta为首均开始大模型的研发与应用;国内以腾讯、阿里巴巴、中科院等为首也投入大模型的研究中,其中也不乏kimi、智谱AI等新兴AI公司也迅速完成LLM落地开发。
但是,此时的各个已经商用的大模型(这里排除掉存在于研究中的部分)主要还是自然语言处理,并不具备图像、语音识别等功能。
博主注:语音识别转文字技术其实已经相当成熟了,但是这里提到的语音识别主要说的是让AI理解声音,比如让AI听出你讲话语气,抑或是可以想象另一种场景,让AI听出来一首歌曲曲风,弹奏乐器等。
2023年3月,OpenAI发布GPT-4模型,相比GPT-3.5,GPT-4在模型大小、参数量、性能等方面都有了质的飞跃,不过,GPT-4的最大亮点是其支持多模态,也就是支持文本和图像形式的Prompt输入。 同期,百度宣布其文心一言模型支持多模态生成。
在这一段时间,多模态的LLM模型开始逐渐走向大众,不仅在科研领域,也在各类应用中得到了广泛的应用,不过大部分应用还是停留在文本和图像的生成,对于语音、视频等多模态的理解还是相对较少。
2023年11月,OpenAI发布了GPT-4 Turbo,新版本GPT-4 Turbo做了六大重要升级:更长的上下文长度、更强的控制、模型的知识升级、多模态、模型微调定制和更高的速率限制。
在此后,各家大模型厂商也相继追赶,纷纷发布了多模态模型,甚至不止于普通的静态图片,也有视频理解,视频生成等多模态应用。 在23年,也有不少AI落地应用,比如说AI客服,AI预诊,Github Copilot等等,AI早已深入我们的生活之中。
当然也有我和洪哥的产品PostChat了(什么王婆卖瓜,逃
LLM的应用--Prompt工程
在阅读完前面的时间线你会发现我提到的基本都是大厂的大语言模型,但是落地的LLM应用却会多很多,总不可能每个开发者或者公司都独立开发LLM吧,毕竟LLM开发不仅需要时间、人力、知识,更重要的是资源,而普通的小厂无法承担这么大的资源开销,并且独自开发LLM效果也未必有大厂提供的API好,因此,对于小厂、开发者来说,使用大厂提供的API是一个不错的选择。
以OpenAI提供的API为例,开发者发送的请求其实也就是普普通通的对话记录。就像这样发送:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer {{OPENAI_API_KEY}}" \
-d '{
"model": "gpt-3.5-turbo",
"messages":
[
{"role": "system", "content": "你是一个代码专家。"},
{"role": "user", "content": "帮我编写一个简单的HTTP服务器的代码"}
]
}'返回Body:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "当然可以。下面是一个使用Go语言编写的简单HTTP服务器示例。这个服务器会在端口8080上监听,并对所有请求返回一个简单的“Hello, World!”消息。\n\n首先,请确保你的机器上已经安装了Go语言环境。如果还没有安装,可以从Go官方网站下载并安装适合你操作系统的版本。\n\n接下来是Go语言代码示例:\n\n```golang\npackage main\n\nimport (\n \"fmt\"\n \"net/http\"\n)\n\n// helloHandler 是处理HTTP请求的函数\nfunc helloHandler(w http.ResponseWriter, r *http.Request) {\n // 设置响应头的内容类型为text/plain\n w.Header().Set(\"Content-Type\", \"text/plain\")\n // 向客户端发送响应体\n fmt.Fprintf(w, \"Hello, World!\")\n}\n\nfunc main() {\n // 注册处理函数到\"/\"路径\n http.HandleFunc(\"/\", helloHandler)\n \n // 在控制台打印服务器启动信息\n fmt.Println(\"Starting server on :8080\")\n \n // 开始监听端口8080\n if err := http.ListenAndServe(\":8080\", nil); err != nil {\n // 如果ListenAndServe返回错误,则打印错误信息并退出程序\n fmt.Printf(\"Error starting HTTP server: %v\\n\", err)\n }\n}\n```\n\n",
"role": "assistant"
}
}
],
"created": 114514,
"id": "chatcmpl-xxxx",
"model": "gpt-3.5-turbo",
"object": "chat.completion"
}在以上的例子中,我们通过POST请求向OpenAI的API发送了一个对话记录,使用model指定使用模型,messages则是对话记录,role指定了对话的角色,content则是对话内容。role有三个值,user、system、assistant,分别代表用户、系统、助手,而我们的Prompt工程则通过system角色来指导模型生成特定的输出。我们输入的聊天记录中role为system让ChatGPT作为一个Go代码专家,此后用户输入内容就不需要指定编写代码的语言,ChatGPT就会使用Go语言来编写代码,就像返回体中的正文内容一样。
所谓Prompt工程其实就是通过自然语言引入合适的模板去管控模型的输入、输出,从而达到我们想要的结果,很多的大模型落地应用便是通过Prompt工程来实现的。
不止于此,单单Prompt并不能满足所有需求,因此OpenAI还提供了一个叫Function call的强大功能,这个功能可以实现让大模型智能调用函数,从而实现更复杂的功能。受限于篇幅,这里就不展开了,感兴趣可以查看Function Call: Chat 应用的插件基石与交互技术的变革黎明
简单实现多模态
大语言模型如其名,本身训练参数是大规模的文字,并不能直接理解图片信息,那么如何实现多模态呢?
在读者必备知识点中,我们讲到了一个概念,OCR,那么现在你可能已经有一些头绪了,在用户提交图片后,我们直接把图片使用OCR技术转换为文本,然后再通过Prompt来指导模型生成特定的输出,如果你能想到这个方法,说明我前面没有白写,没想到也没关系,都是我的问题,一定是我没写明白!
实现流程可以简化为:
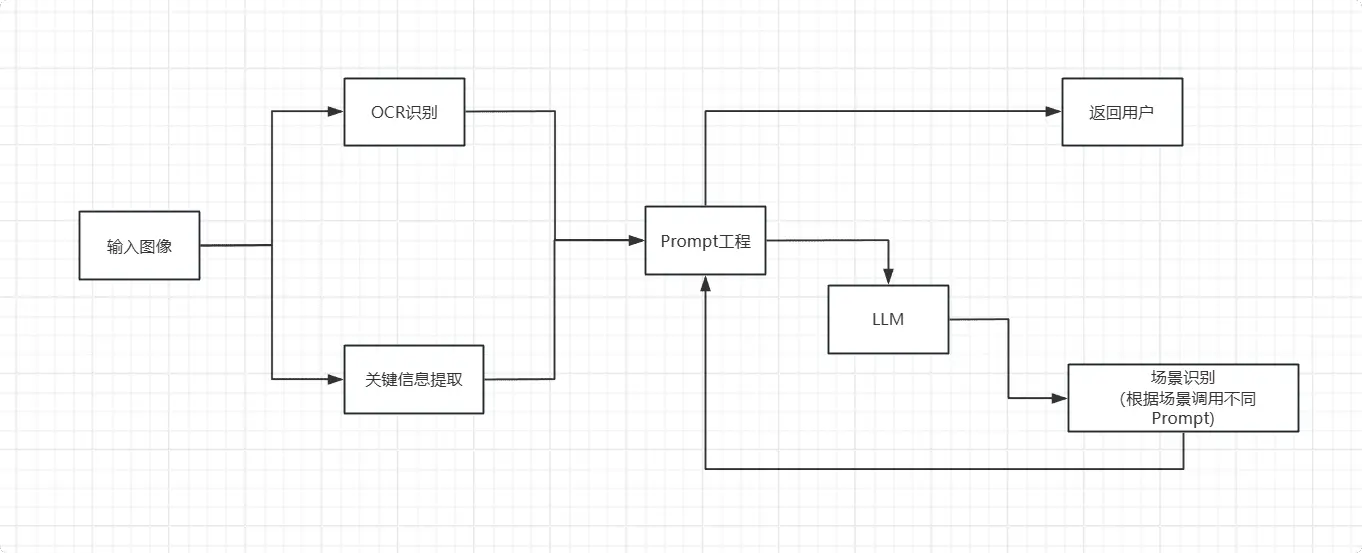
博主注:在实际多模态大模型实现过程中更为复杂,包括 多模态预训练、跨模态映射、联合学习任务等,具体可参考这篇论文:General Object Foundation Model for Images and Videos at Scale
OCR如何做到图片转文字
拓展内容,不影响主线,有兴趣的读者可以继续阅读,不感兴趣的读者可以跳过,你只需要知道
OCR能完成的功能就行。
深度理解可参考:一文讲通OCR文字识别原理与技术全流程
光学字符识别(英语:Optical Character Recognition,缩写:OCR)是指对包含文本内容的图像或视频进行处理和识别,并提取其中所包含的文字及排版信息的过程。
你可能不知道,OCR已经发展很多年了:
1929年,德国科学家Taushecki最先提出,并申请专利。
1970年代,OCR技术开始商业化,IBM、东芝研发出了第一代OCR设备,用于识别邮编。
2013年,开发出了深度学习OCR技术,大大提高了识别准确率。
到现在,OCR的实现主要有以下流程:
输入图像 -> 前期处理 -> 中期处理 -> 后期处理 -> 输出文本
前期处理:主要是对图像进行预处理,包括灰度化、二值化、去噪、倾斜矫正等。
在图像处理中,我们感兴趣的内容是文本,但是摄像头拍摄或者网络图像大多是彩色图像,为了方便计算机处理,我们需要将彩色图像转换为灰度图像,然后再进行二值化处理,将图像转换为黑白图像,这样可以减少计算量,提高识别准确率,你可以将二值化简单理解为图像黑白化。
而降噪则是为了去除图像中的干扰信息,提高识别准确率,在不同的图像中,我们对噪声的定义不同,但是道理一样,我们需要去除干扰信息,只提取我们感兴趣的内容。
倾斜矫正则是为了解决图像中文本倾斜的问题,无论图片如何畸变、旋转都需要让电脑正确找到文字的正向区域,这个问题在拍摄的时候就会出现,如果不进行矫正,会影响识别准确率,就比如你斜着去看屏幕或书,看文字会有点困难。
中期处理:主要是对图像进行版面分析,,,版面还原等。
版面分析即将图片分段,但是考虑到实际情况,此算法并不通用。
字符切割是将图片中的字符切割出来,比如有这两个字
亻子,究竟是仔还是亻子,这就需要字符切割来解决,在实际算法中,一般会使用、等算法。字符识别是将切割出来的字符识别为文字,这个过程是OCR的核心,因为不同的字体、大小、颜色、背景等都会影响识别的效果。得益于深度学习的发展,现在可以依靠各种卷积神经网络模型进行处理,OCR字符识别已经十分简单了。
版面还原是将识别出来的文字还原到原图中,这个过程是为了让用户更好的理解识别结果,但是在实际应用中,这个过程并不是必须的,不过在一些特殊场景下,还原版面是十分重要的,比如文字翻译,将识别出来的文字翻译后还原到原图中,会让你更直观清晰的看懂翻译结果。
后期处理:主要是对识别结果进行校正,提高识别准确率。
在OCR识别中,我们可能会出现一些错误,比如
O和0、l和1、i和1等,这些都是OCR识别的问题,为了提高识别准确率,我们需要对识别结果进行校正,我们可以根据自然语言逻辑、词典、语法等进行校正。比如,我有一段文字今天我去沃尔玛买了1个苹果,这个苹果只需要5块钱,我就给收银员10元让他找钱,收银员比了个手势OK,这段文字中,1个苹果,10元,5块钱,手势OK很容易被识别错误,但是根据逻辑,我们可以很容易的校正。输出文本:将识别结果输出为文本。
简单的多模态实现--OCR+Prompt
咱们以这篇论文的摘要部分截图为例子: II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models

首先先配置好我们的运行环境,需要你前往tesseract Release找到最新
Release,下载Setup.exe的文件,在选择语言包的时候,你如果有需求记得勾选Chinese Simplified,然后一路下一步就行。(其实Windows10开始已经自带了OCR,但是Python部分库已经不维护了,所以这里不使用Windows SDK的OCR)安装好
tesseract之后,我们需要安装pytesseract库和pillow库,这两个库分别用于调用tesseract和处理图片。
pip install pytesseract pillow然后新建一个main.py文件,写入以下代码:
from PIL import Image
import pytesseract
# 设置tesseract的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 打开图片文件
image_path = './images/1.png' # 你的图片路径,这里使用相对路径存放在images文件夹下
image = Image.open(image_path)
# 使用Tesseract进行OCR处理
text = pytesseract.image_to_string(image, lang='chi_sim') # 对于简体中文可使用'chi_sim',如果你未安装简体中文库,则使用'eng'
# 输出识别的文字
print(text)运行main.py,打印如下
The rapid advancements in the development of multimodal large language models (MLLMS) have consis-
tently led to new breakthroughs on various benchmarks. In response, numerous challenging and compre-
hensive benchmarks have been proposed to more accurately assess the capabilities of MLLMS. However
there is a dearth of exploration of the higher-order perceptual capabilities of MLLMSs. To fill this gap, we pro-
pose the Image Implication understanding Benchmark, I-Bench, which aimas to evaluate the models higher-
order perception of images. Through extensive experiments on II-Bench across multiple MLLMS, we have
made significant findings. Initially a substantial gap is observed between the performance of MLLMs and
humans on II-Bench. The pinnacle accuracy of MLLMSs attains 74.8%,whereas human accuracy averages
90%, peaking at an impressive 98%. Subsequently MLLMSsS perform worse on abstract and complex images,
suggesting limitations in their ability to understand high-level semantics and capture image details. Finally 让
is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorpo-
rated into the prompts. This observation underscores anotable deficiency in their inherent understanding of
image sentiment. We believe that II-Bench will inspire the commumnity to develop the next generation of
MLLMs, advancing the journey towards expert artificial general intelligence (AGD. II-Bench is publicly avail-
able at https://huggingface.co/datasets/m-a-p/II-Bench.可以看到,识别的效果还是不错的,除了断句问题,基本上识别的都是正确的,不过这些都可以通过算法以解决,这里主要讲解的是如何实现多模态,所以就不展开了。
那有了以上的文字,我们就可以通过Prompt来指导模型生成特定的输出,从而实现简单的多模态。接下来我们要做的就是将这个文本和Prompt结合起来,然后发送给LLM模型。
- 通过以上的
Prompt工程讲解,相信你已经有一些眉目了,所以接下来我们先想好我们的Prompt,然后再拼接文本,最后发送给LLM模型,下面{content}将会插入我们的识别文本结果。我这里的Prompt是这样的:
现在,你是一个AI助手,我通过OCR识别出了一段文本,内容如下“\n{content}\n”,请你讲解一下这段文本主要讲述研究人员做了什么工作,请详细解释。- 根据以上的示例请求,我们可以知道主要是通过
POST请求发送给OpenAI的API,所以我们需要安装requests库。
pip install requests- 然后我们继续修改
main.py文件,写入以下代码:
from PIL import Image
import pytesseract
import requests
import json
# 设置tesseract的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 打开图片文件
image_path = './images/1.png'
image = Image.open(image_path)
# 使用Tesseract进行OCR处理
ocrtext = pytesseract.image_to_string(image, lang='chi_sim')
# 输出识别的文字
print("识别结果:", ocrtext)
# 请求ChatGPT生成文本
api_url = "https://ai.tianli0.top/v1/chat/completions" # 你的API地址,我这里使用的咱PostChat的兼容API地址
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer sk-114514" # 你的API Key,我这里随便写的,实际上跑不起来,如果你恰好有咱的PostChat的API Key,可以使用
}
prompt=f"现在,你是一个AI助手,我通过OCR识别出了一段文本,内容如下“\n{ocrtext}\n”,请你讲解一下这段文本主要讲述研究人员做了什么工作,请详细解释。"
# 请求体
data = {
"model": "gpt-3.5-turbo",
"messages":
[
{"role": "user", "content": prompt},
]
}
# 发送请求
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# 输出完整的返回结果
print(response.json())运行main.py,你会看到如下输出:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "这段文本主要讲述研究人员开发了一个新的基准测试,名为Image Implication understanding Benchmark(简称I-Bench),用于评估多模态大型语言模型(MLLMS)在图像高层感知能力方面的表现。研究人员通过在I-Bench上进行广泛的实验,发现MLLMS在理解图像高层语义和捕捉图像细节方面存在一定的局限性,尤其是在处理抽象和复杂的图像时。此外,研究还发现大多数模型在图像情感极性提示被整合到提示中时,准确率有所提高,这表明模型在理解图像情感方面存在明显的不足。研究人员希望通过I-Bench激发社区开发下一代MLLMS,以推动人工通用智能(AGI)的发展。",
"role": "assistant"
}
}
],
"created": 1731495503,
"id": "20241113185815e13fa8b8262a4b68",
"request_id": "20241113185815e13fa8b8262a4b68",
"usage": {
"completion_tokens": 150,
"prompt_tokens": 4022,
"total_tokens": 4172
}
}可以看到,我们通过Prompt成功让AI生成了我们想要的文本,这就是简单的多模态实现。
不止于识别文字
文字描述是计算机视觉的一个重要分支,其功能是使计算机能够理解和描述图像中的内容,这是一种多模态学习的应用,也是大型语言模型的一个重要应用场景。
当然,现在的大模型不止于简简单单的图片文字信息理解,它也能理解更多的信息,比如说你可以给它发一张狗狗的照片,让他分辨这是什么品种的狗狗。就像这样 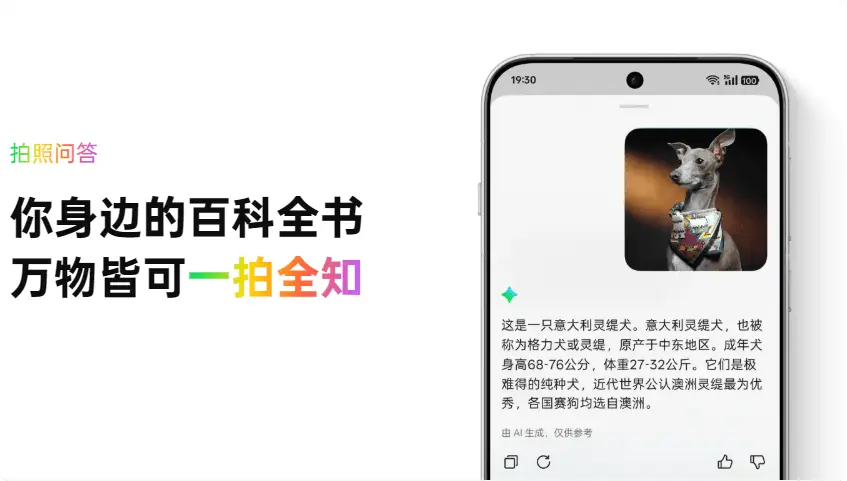 大语言模型图像感知
大语言模型图像感知
那么,这种级别的算法是如何实现的呢?
这就涉及到了多模态预训练、跨模态映射、联合学习任务等,不过既然我们不能实现这么复杂的算法,那我们能不能依靠已有技术来实现呢?
答案是肯定的,我们可以通过调用已有的API来实现,比如说我们可以通过Robotic Transformer 2来实现图片描述,将图片信息转换为文字描述信息,同样的,再通过Prompt工程来指导模型生成特定的输出。
Robotic Transformer 2的实现原理请参考原论文:RT-2: New model translates vision and language into action
主流实现
主流实现还是通过Transformer模型,Transformer模型是一种基于注意力机制的神经网络模型,它在自然语言处理领域取得了巨大成功,因此也被广泛应用于计算机视觉领域,实现图像描述、图像生成等任务。 它通过对输入序列中的不同位置进行自注意力计算,从而实现了对序列信息的全局建模。在图像描述任务中,transformer可以用来处理图像特征的编码和生成文字描述的解码过程。通过自注意力机制,transformer能够捕捉到图像中不同区域的语义关联,从而生成更准确、更有表现力的图像描述。
Robotic Transformer 2
Robotic Transformer 2是由DeepMind提出的一种新型模型,它能够将视觉和语言信息转换为动作。RT-2模型通过联合训练视觉和语言模块,实现了从图像和文本到动作的端到端学习。
DeepMind提出了他们的机器人大模型Robotic Transformer 2(RT2),展现出了出色的语义理解和视觉理解能力。这一模型在许多任务中展现出了惊人的表现,例如帮助疲倦的人选择最适合的饮料。
RT2的强大之处在于它能够同时处理语义和视觉信息,从而实现对多模态任务的高效处理。对于上述的例子,当面对一个疲倦的人时,RT2可以通过语义理解和视觉分析,准确判断出他们的需求,并选择出最适合的饮料。RT2的语义理解能力使其能够理解人类的需求和意图,通过对语言输入的处理,它能够准确地解析出人们所表达的需求。同时,RT2的视觉理解能力使其能够分析和理解图像或视频中的内容,从中获取关键信息。通过将这两种能力结合起来,RT2能够在多模态任务中取得出色的表现。

拓展--Vit模型实现图生文
进阶内容,可跳过,不影响后文理解。
原论文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Vit 是谷歌在2020年提出的图像分类模型,因其简单,且效果好,可拓展性强,被CV领域广泛应用。
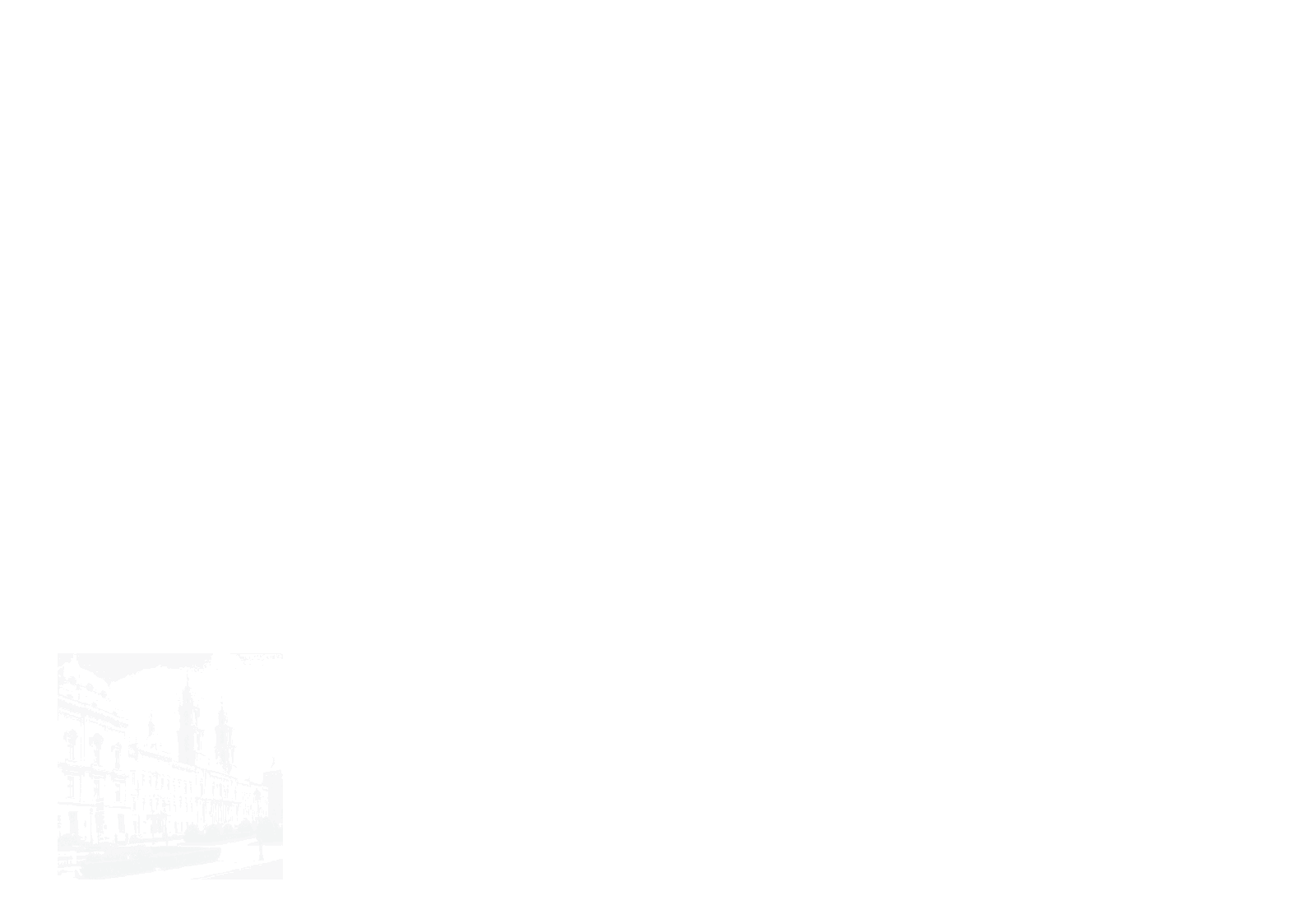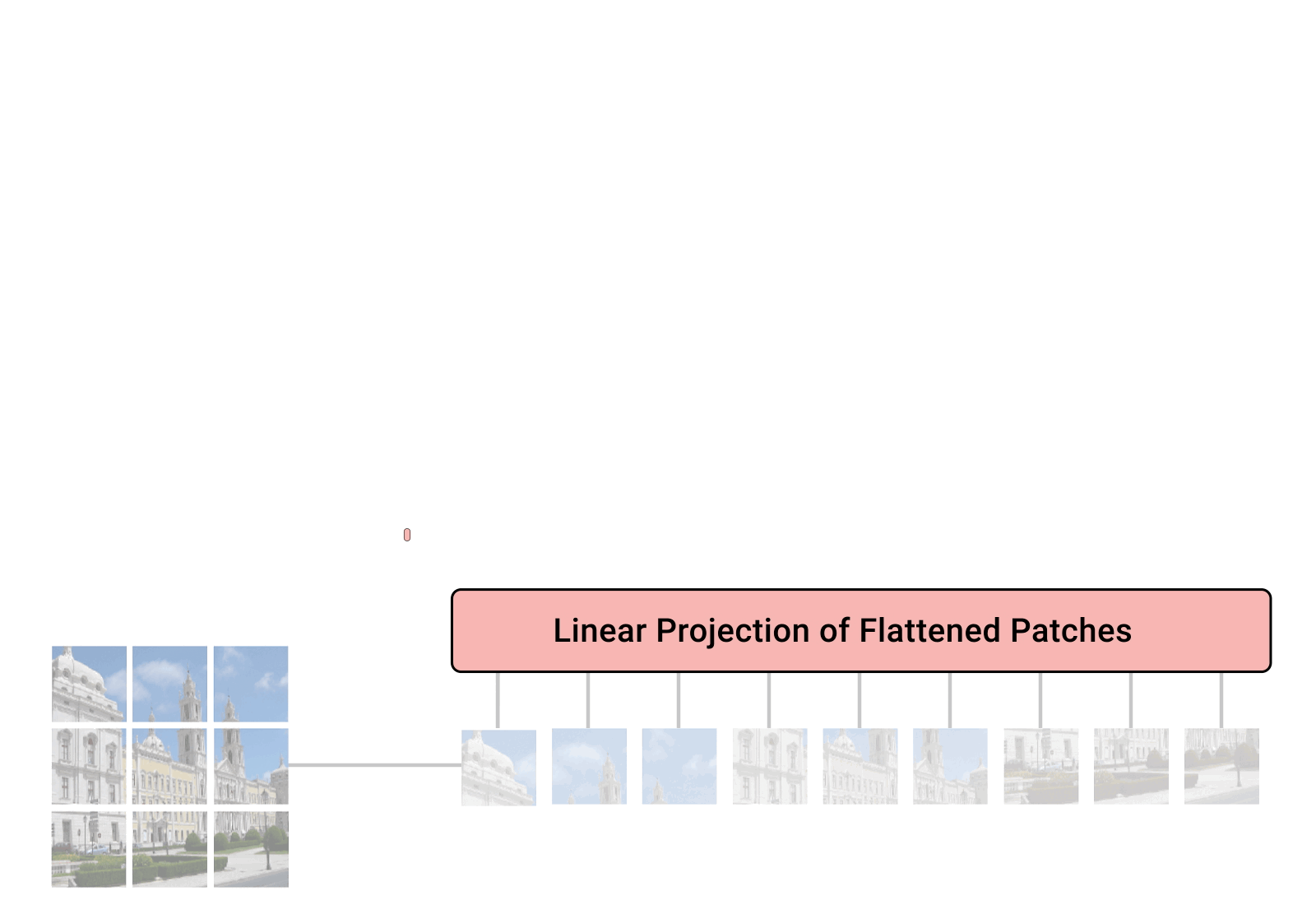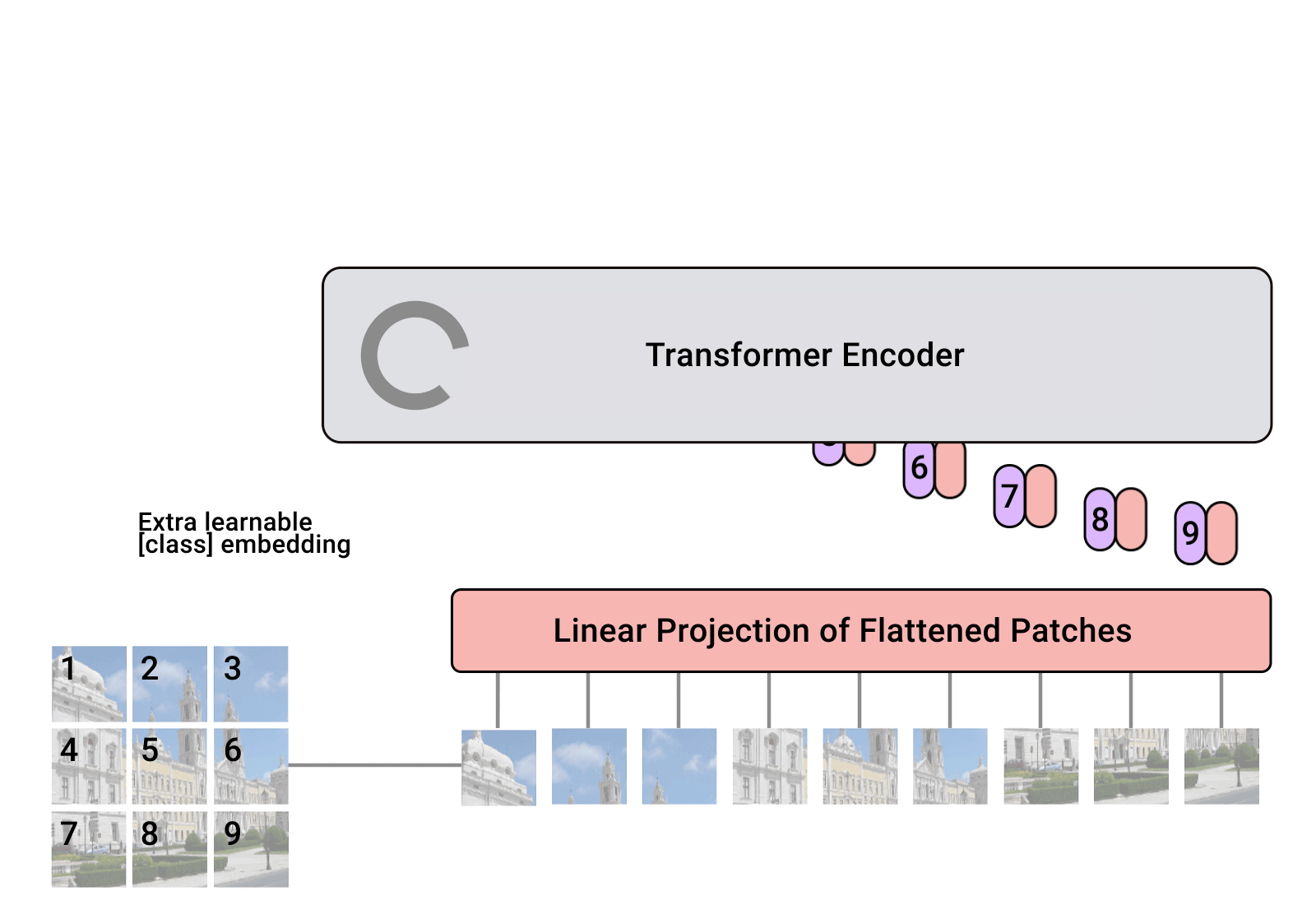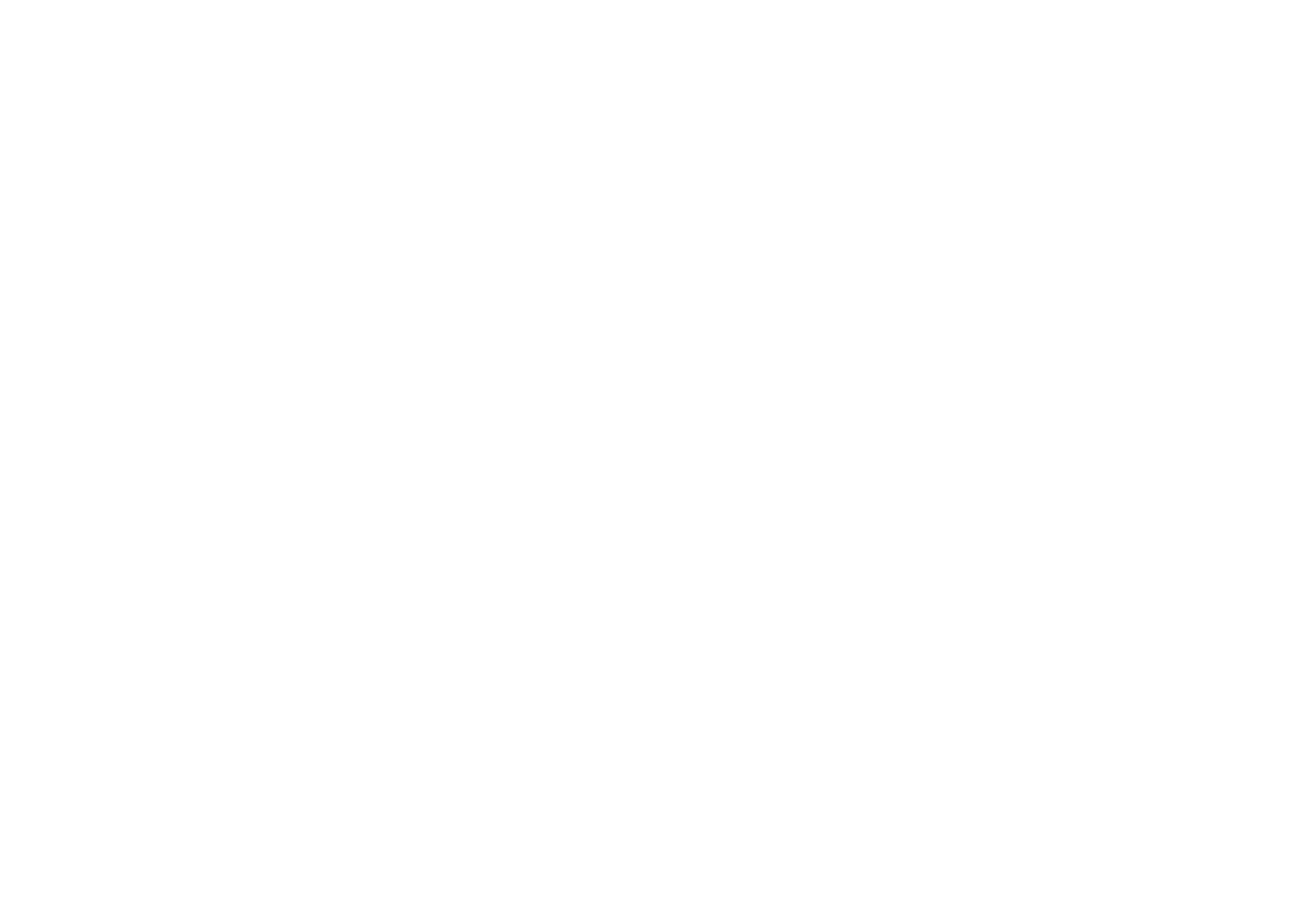
参考这个动画,我们可以看见Vit模型是如何将图片转换为文本的:
首先,ViT将输入图片分为多个patch(16x16)
将其转换为Patch Embeddings
添加位置编码信息
通过包含多头自注意力和前馈神经网络的Transformer编码器处理这些嵌入
最后,通过一个MLP头输出分类结果
模型主要由三个模块构成:
- Embedding:将输入图像分割为固定大小的patch,并将每个patch转换为一个向量,然后添加位置编码。
在Transformer架构中,输入的一般是二维矩阵,(N,D),其中N是序列长度,D是每个元素的维度。但是图像是三维的,(H,W,C),其中H是高度,W是宽度,C是通道数。为了将图像转换为Transformer可以处理的形式,我们首先将图像分割为固定大小的patch,然后将每个patch转换为一个向量。这些向量被称为patch embeddings。
Transformer Encoder:Transformer编码器由多个Transformer块组成,每个块包含多头自注意力和前馈神经网络。在ViT中,我们使用标准的Transformer块,但是我们将其应用于patch embeddings而不是序列。
MLP Head:最后,我们将Transformer的输出传递给一个多层感知机(MLP)头,以输出图像的类别。
简单的多模态实现--图片描述预训练模型+OCR+Prompt
此章节需要用到
Transformerhuggingface等,所以这里需要配置较为复杂的运行环境,如果你不打算实现,仅需要理解代码逻辑即可,可以跳过。
到这里,你肯定看见标题就知道我要干什么了,没错,同样的,我们使用图片描述预训练模型来实现图片信息的多模态,然后再通过Prompt工程来指导模型生成特定的输出。
在这里我们使用已经训练好的模型:vit-gpt2-image-captioning,此模型仅具备基础能力,若有需要,请自行学习并了解huggingface。
测试示例图片如下: 示例图片
示例图片
- 首先我们需要安装
transformers库,这个库是huggingface提供的,用于调用预训练模型。
pip install transformers- 然后我们先写一个基础的输出图片描述的代码,这里我们使用
vit-gpt2-image-captioning模型,代码如下:
from PIL import Image
from torchvision import transforms
import torch
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
# 读取本地图片文件
image_path = './images/2.jpg' # 图片文件的路径
image = Image.open(image_path) # 打开图片文件
# 转换图片为 tensor
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的特征提取器
transform = transforms.Compose([
# transforms.Resize((224, 224)), # 调整图片大小 合适的大小将有助于提高模型的性能
transforms.ToTensor() # 将图片转换为Tensor
])
img = transform(image).unsqueeze(0) # 应用转换并增加一个维度以匹配模型输入
# 加载预训练的图像描述模型
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的图像描述模型
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的分词器
# 将图片转换为特征
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values # 使用特征提取器将图片转换为模型输入所需的特征
# 生成描述
output_ids = model.generate(pixel_values, max_length=16, num_beams=4) # 生成图像描述,设置最大长度为16,使用4个beam search
description = tokenizer.decode(output_ids[0], skip_special_tokens=True) # 解码生成的描述,跳过特殊标记
print("图片描述:", description)运行main.py,你会看到在下载完成模型后有如下输出:
图片描述: a man in a band playing a guitar可以看到,当前的图片描述算是符合图片实际的,那么接下来我们就可以把他加到前面OCR那一节的代码中,然后再通过Prompt工程来指导模型生成特定的输出。
- 然后我们继续修改
main.py文件,写入以下代码:
from PIL import Image
from torchvision import transforms
import torch
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
from PIL import Image
import pytesseract
import requests
import json
# 设置tesseract的安装路径
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 打开图片文件
image_path = './images/2.jpg' # 图片文件的路径
image = Image.open(image_path)
# 使用Tesseract进行OCR处理
ocrtext = pytesseract.image_to_string(image, lang='chi_sim')
# 输出识别的文字
print("识别结果:", ocrtext)
# 转换图片为 tensor
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的特征提取器
transform = transforms.Compose([
# transforms.Resize((224, 224)), # 调整图片大小 合适的大小将有助于提高模型的性能
transforms.ToTensor() # 将图片转换为Tensor
])
img = transform(image).unsqueeze(0) # 应用转换并增加一个维度以匹配模型输入
# 加载预训练的图像描述模型
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的图像描述模型
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 加载预训练的分词器
# 将图片转换为特征
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values # 使用特征提取器将图片转换为模型输入所需的特征
# 生成描述
output_ids = model.generate(pixel_values, max_length=16, num_beams=4) # 生成图像描述,设置最大长度为16,使用4个beam search
description = tokenizer.decode(output_ids[0], skip_special_tokens=True) # 解码生成的描述,跳过特殊标记
print("图片描述:", description)
# 请求ChatGPT生成文本
api_url = "https://ai.tianli0.top/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer sk-114514"
}
prompt=f"现在,你是一个AI助手,我通过OCR识别出了一段文本,内容如下“\n{ocrtext}\n”,同时图片描述如下“\n{description}\n”,请你讲解一下这张图片详细信息。"
# 请求体
data = {
"model": "chatgpt-3.5-turbo",
"messages":
[
{"role": "user", "content": prompt},
]
}
# 发送请求
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# 输出完整的返回结果
print(response.json())运行main.py,你会看到如下输出:
{
"content": "根据您提供的文本和图片描述,我们可以这样理解:\n\n文本内容:“真我GT5 Pro 183mm fl12.6 11/31s ISO640”\n- “真我GT5 Pro”可能指的是一部手机的型号。\n- “183mm”可能 表示手机的长度或者与拍摄有关的一个参数。\n- “fl12.6”可能是摄影中的焦距和光圈的组合表示。\n- “11/31s”可能指的是快门速 度,即11分之一秒。\n- “ISO640”是感光度的一种表示,通常用于摄影中,表示相机的感光度设置为640。\n\n图片描述:“a man in a band playing a guitar”\n- “a man”指的是一个男性。\n- “in a band”表明这个男性是乐队成员。\n- “playing a guitar”说明 他在演奏吉他。\n\n综合两者,这张图片可能拍摄的是一个男性乐队成员在演奏吉他的场景,而提供的文本信息可能是在描述与这个 场景相关的摄影参数或者是手机的相关信息。这些信息结合起来,可以推测这张图片是一张关于乐队现场表演的照片,而文本则是提 供了拍摄该照片时相机的设置参数。",
"role": "assistant",
"created": 1731510295,
"id": "202411132304472a78066dec87422b",
"request_id": "202411132304472a78066dec87422b",
"usage": {
"completion_tokens": 273,
"prompt_tokens": 3661,
"total_tokens": 3934
}
}可以看到,AI正确理解了图片,并给出了详细的解释,已经达到我们的目的了。
总结
到这里,想必你已经对多模态实现有了自己的想法吧?不论你懂不懂代码,懂不懂深度学习,只要你能了解到这个过程,那总有一天你能实现自己的无限想象。
问卷调查
在本篇学习笔记中,在多处使用了AI快捷搜索对话功能,作为读者,你认为这种功能对你的文章阅读有帮助吗?您可点击以下链接参与问卷调查,帮助我们更好地改进产品,本次问卷为有奖问卷,包括PostChat会员和现金奖励,感谢您的参与!点击参与问卷调查
参考文献
仅展示未在文章中引用的参考文献