实验笔记,仅做记录,不作为参考。
Ultralytics 是YOLOv8(v11)的代码仓库,YOLOv11是一个很常见的图像目标检测的机器学习库,其性能在YOLO众多版本中表现出色。
基础环境安装
除开最基础的Python环境外,还需要安装CUDA、Pytorch、torchvision等库。
推荐使用
conda进行环境管理,可以避免环境污染,以下使用pip进行安装。
- 首先检查当前显卡支持的CUDA版本,然后安装对应的CUDA版本,可以通过
nvidia-smi命令查看显卡信息。
nvidia-smi输出如下:
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 566.07 Driver Version: 566.07 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 ... WDDM | 00000000:01:00.0 On | N/A |
| N/A 54C P0 28W / 130W | 1543MiB / 6144MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+前往Pytorch官网查看支持的CUDA版本,然后安装对应的Pytorch版本,无NVIDIA显卡的安装CPU版本。
安装CUDA,可以通过CUDA官网下载对应的CUDA版本,然后安装。
安装Pytorch,可以通过Pytorch官网下载对应的Pytorch版本,然后安装,以
pip,CUDA 12.4,pytorch stable为例:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124- 安装
Ultralytics,可以通过pip安装,保险起见,这里使用git仓库安装(原因可查看:Ultralytics(YOLOv8/v11) 投毒事件分析):
pip install git+https://github.com/ultralytics/ultralytics.git代码拉取
为了后续我们对YoLoV11的神经网络进行修改,此处仍需拉取Ultralytics的代码仓库,然后进行训练。
- 拉取
Ultralytics代码仓库:
git clone https://github.com/ultralytics/ultralytics.git数据集准备
在训练之前,YOLO使用的数据集格式为COCO格式,可以通过labelme工具进行标注,然后转换为COCO格式。
在此处,我们已准备好数据集,以TT100K为例,数据集已经转换为COCO格式。
Tsinghua-Tencent 100K 是清华大学与腾讯发布的大规模交通标志数据集,原数据集无法直接使用于YOLO训练,因此发布经过清洗后的TT100K数据集,用于训练交通标志检测模型。
对于基础的YOLO通用模型来说,此数据集较为复杂,具体表现为以下问题:
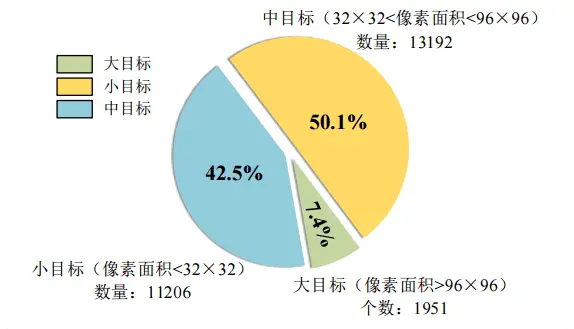
由于交通标志距离车身摄像头较远,其中有用信息占用图像较小区域,导致小目标检测困难,难以提取到有效特征。 在TT100K交通标志数据集中,42.5%的交通标志样本都属于小目标,大目标仅占比7.5%。
交通标志种类繁多,目标高达232种,对于罕见交通标志样本数量较少,且各地可能出现差异化,且专门采集罕见的交通标志数据会大幅度提高数据采集成本,仍然表现出较为明显的长尾问题。
环境复杂,由于天气、光照、背景等因素,导致交通标志样本难以提取有效特征。

我们任意挑选一张验证批次图查看:

可以看见,检测难度较高。
训练
YoloV11的训练过程较为简单
使用CLI
基础CLI指令使用非常简单:
yolo TASK MODE ARGS
Where TASK (optional) is one of [detect, segment, classify, pose, obb]
MODE (required) is one of [train, val, predict, export, track, benchmark]
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.其中:
TASK (可选),可使用[
detect,segment,classify,pose,obb]中的一个。MODE (必选),可使用[
train,val,predict,export,track,benchmark]中的一个。ARGS (可选),可以使用任意数量的自定义
arg=value对,如imgsz=320,覆盖默认值。
解释如下:
detect:检测任务,用于检测目标。segment:分割任务,用于分割目标。classify:分类任务,用于分类目标。pose:姿态任务,用于检测目标姿态。obb:用于检测目标的方向。train:训练模式,用于训练模型。val:验证模式,用于验证模型。predict:预测模式,用于预测模型。export:导出模式,用于导出模型。track:跟踪模式,用于跟踪目标。benchmark:基准模式,用于基准测试。
在此处,我们使用train模式进行训练,以TT100K数据集为例:
yolo detect train data.yaml --img 640 --batch 16 --epochs 300 --weights yolov11s.pt其中:
data.yaml:数据集配置文件,用于指定数据集路径、类别等信息。--img 640:指定输入图像大小为640。--batch 16:指定批次大小为16。--epochs 300:指定训练轮数为300。--weights yolov11s.pt:指定预训练模型为yolov11s.pt。
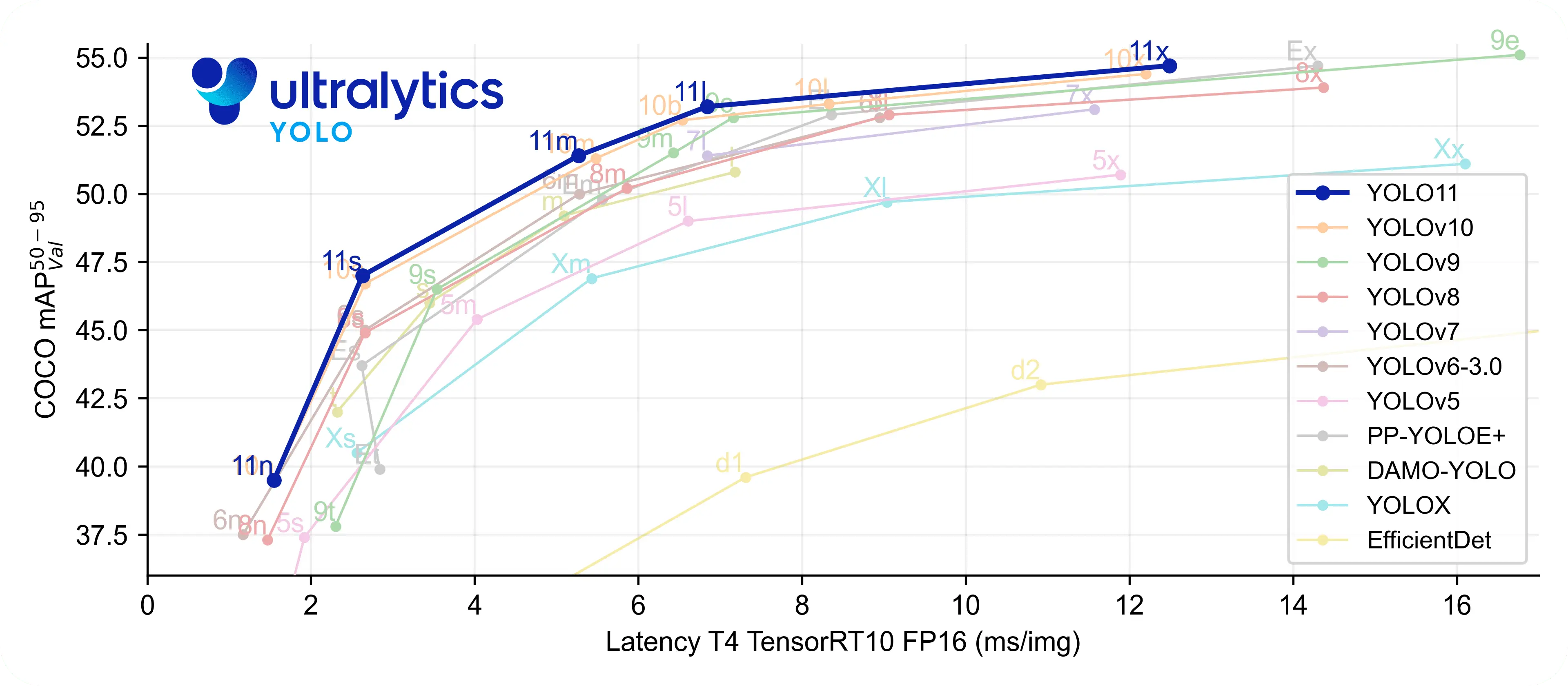
通过此图,我们也能看见为什么选择yolov11作为预训练模型。
使用Python
在Python中,我们可以使用Ultralytics提供的API进行训练,以TT100K数据集为例:
from ultralytics import YOLO
# Load a pre-trained YOLO model (you can choose n, s, m, l, or x versions)
model = YOLO("yolo11n.pt")
# Start training on your custom dataset
model.train(data="path/to/dataset.yaml", epochs=100, imgsz=640)其中的参数参考CLI指令。